3.1.
модули оперативной памяти
3.1.1.
Принципы хранения информации в оперативной динамической
памяти
Динамическая память — DRAM (Dynamic RAM)
— получила свое название от принципа
действия ее запоминающих ячеек, которые выполнены в виде конденсаторов,
образованных элементами полупроводниковых микросхем. С некоторым
упрощением описания физических процессов можно сказать, что при
записи логической единицы в ячейку конденсатор заряжается, при
записи нуля — разряжается.
Схема считывания разряжает через себя этот конденсатор, и, если
заряд был ненулевым, выставляет на своем выходе единичное значение,
и подзаряжает конденсатор до прежнего значения. При отсутствии
обращения к ячейке со временем за счет токов утечки конденсатор
разряжается и информация теряется, поэтому такая память требует
постоянного периодического подзаряда конденсаторов (обращения
к каждой ячейке) — память
может работать только в динамическом режиме. Этим она принципиально
отличается от статической памяти, реализуемой на триггерных ячейках
и хранящей информацию без обращений к ней сколь угодно долго (при
включенном питании). Благодаря относительной простоте ячейки динамической
памяти на одном кристалле удается размещать миллионы ячеек и получать
самую дешевую полупроводниковую память достаточно высокого быстродействия
с умеренным энергопотреблением, используемую в качестве основной
памяти компьютера. Расплатой за низкую цену являются некоторые
сложности в управлении динамической памятью, которые будут рассмотрены
ниже.
3.1.2.
Внутренняя организация микросхем DRAM
Запоминающие ячейки
микросхем DRAM организованы в виде двумерной матрицы. Адрес строки и
столбца передается по мультиплексированной шине адреса МА
(Multiplexed Address) и стробируется
по спаду импульсов RAS# (Row Access Strobe)
и CAS# (Column Access Strobe).
Временная диаграмма “классических” циклов записи и чтения имеет
следующий вид.
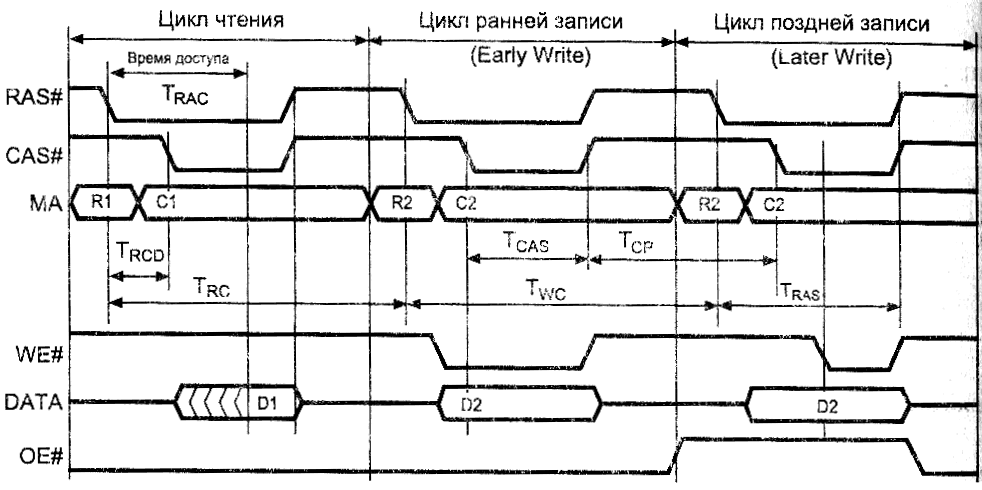
Рис.1. Временные
диаграммы чтения
и записи DRAM
Поскольку обращения
(запись или чтение) к различным ячейкам памяти обычно происходят
в случайном порядке, то для поддержания сохранности данных применяется
регенерация (Memory Refresh —
“освежение” памяти) — регулярный
циклический перебор ее ячеек (обращение к ним) с холостыми циклами.
Регенерация в микросхеме происходит одновременно по всей строке
матрицы при обращении к любой из ее ячеек. Максимальный период
обращения к каждой строке ТRF (refresh time)
для гарантированного сохранения информации у современной памяти
лежит в пределах 8-64 мс.
В зависимости от объема и организации матрицы для однократной
регенерации всего объема требуется 512, 1024, 2048
или 4096 циклов обращений. При распределенной регенерации
(distributed refresh) одиночные циклы
регенерации выполняются равномерно с периодом tRF
(рис.2,а), который для стандартной памяти принимается равным
15,6 мкс. Период этих циклов
называют “refresh rate”, хотя такое название больше подошло бы к обратной величине
— частоте циклов f= l/tRF.
Для памяти с расширенной регенерацией (extended refresh)
допустим период циклов до 125
мкс. Возможен также и вариант пакетной регенерации
(burst refresh), когда все циклы
регенерации собираются в пакет (рис.2,6), во время которого обращение к памяти по чтению и записи
блокируется. При количестве циклов 1024
эти пакеты будут периодически занимать шину памяти примерно на
130 мкс, что далеко не всегда допустимо,
По этой причине практически всегда выполняется распределенная
регенерация, хотя возможен и промежуточный вариант — пакетами по нескольку (например, 4)
циклов.
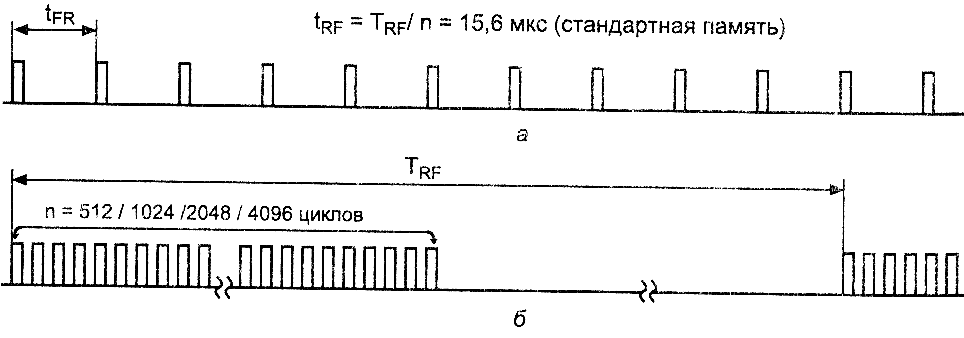
Рис.2. Методы регенерации динамической памяти
Циклы регенерации могут организовываться разными способами.
Классическим является цикл без импульса СА5# (рис.3,а),
сокращенно именуемый ROR (RAS Only Refresh —
регенерация только импульсом RAS#). В этом случае адрес очередной регенерируемой строки выставляется
контроллером памяти до спада RAS#
очередного цикла регенерации, порядок перебора регенерируемых
строк не важен.
Другой вариант
— цикл CBR (CAS Before
RAS), поддерживаемый практически
всеми современными микросхемами памяти (рис.3,б).
В этом цикле регенерации спад импульса RAS# осуществляется при низком уровне сигнала CAS#
(в обычном цикле обращения такой ситуации не возникает). В этом
случае микросхема выполняет регенерацию строки, адрес которой
находится во внутреннем счетчике микросхемы, и в задачу
контроллера входит только периодическое формирование таких циклов.
Во время спада RAS# сигнал
WE# должен находиться в состоянии
высокого уровня. Дополнительным преимуществом данного цикла является
экономия потребляемой мощности за счет неактивности внутренних
адресных буферов,
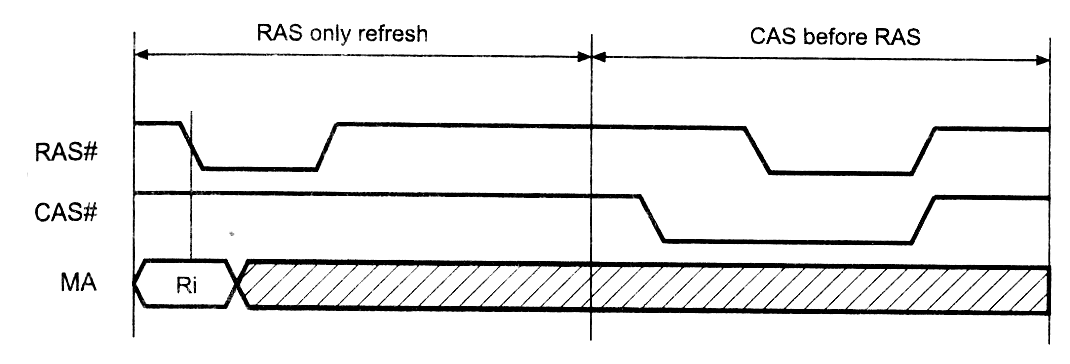
Рис.3. Циклы регенерации динамической памяти
Микросхемы синхронной динамической памяти выполняют
циклы CBR по команде Auto Refresh. А по команде Self
Refresh или Sleep Mode они выполняют автономную регенерацию
в энергосберегающем режиме. Такой возможностью обладают некоторые
современные микросхемы, имеющие внутренний генератор, Вход в режим
осуществляется как в цикл CBR, но сигнал RAS# должен быть активен
более 100 мкс. Информация в таком состоянии будет храниться сколь
угодно долго при наличии питающего напряжения. Выход из этого
“спящего” состояния осуществляется по подъему сигналов RAS# и
CAS#.
Цикл скрытой
регенерации (hidden refresh)
является разновидностью цикла CBR:
здесь в конце полезного цикла чтения или записи сигнал
CAS# удерживается на низком уровне, a RAS#
поднимается и снова опускается, что и является указанием микросхеме
на выполнение цикла регенерации по внутреннему счетчику (рис.4).
При этом слово “скрытость не всегда означает экономию времени
(затраты на регенерацию остаются теми же. что и в обычном
CBR, хотя в принципе возможно предельное
укорочение активной части импульса CAS# при
чтении). Во время скрытой регенерации после цикла чтения выходные
буферы сохраняют только что считанные данные (в обычном
CBR выходные буферы находятся в высокоимпедансном
состоянии).
Регенерация основной
памяти в PC/XT осуществлялась каналом DMA-0. Сигнал Refr, вырабатываемый
каждые 15,6 мкс по сигналу
от первого канала таймера-счетчика 8253/8254
(порт 041h), вызывает холостой
цикл обращения к памяти для регенерации очередной строки. В
PC/AT контроллер регенерации усложнен. В современных компьютерах
регенерацию основной памяти берет на себя чипсет, и его задача
— по возможности использовать для регенерации циклы шины,
не занятые ее абонентами (процессорами и активными контроллерами).
Самые “ловкие” контроллеры регенерации (smart refresh) ставят запросы на регенерацию в очередь, которую обслуживают
в свободное для шины время, и только если запросов накапливается
больше предельного количества откладывается текущий цикл обмена
по шине и цикл регенерации выполняется немедленно. Модули памяти
в разных банках могут регенерироваться одновременно, но при использовании
чередования (interleaving) для экономии времени целесообразно производить регенерацию
одного банка во время полезного обращения к другому. Некоторые
системные платы позволяют использовать режим пониженной частоты
регенерации (slow refresh), однако его можно применять только с модулями памяти, допускающими
режим Extended Refresh.
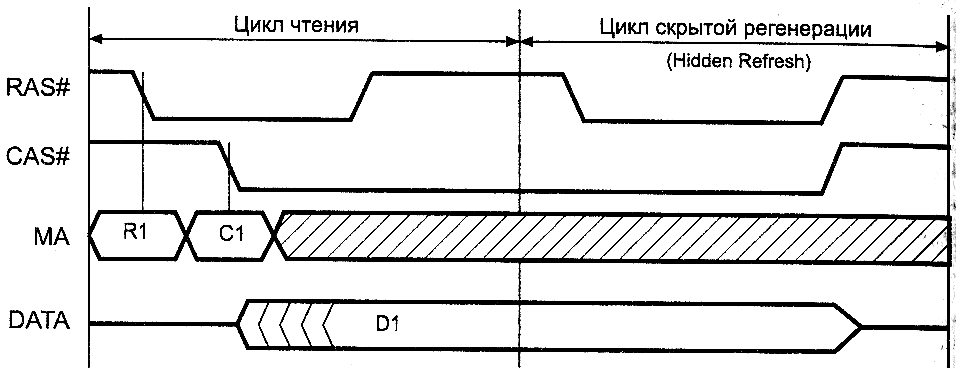
Рис.4. Скрытая регенерация (Hidden Refresh)
Динамическая память, используемая в видеобуферах
графических адаптеров, регенерации не требует, т.к. видеоадаптер
постоянно читает видеопамять для того, чтобы периодически формировать
изображение на экране. Этого вполне достаточна для регенерации
информации.
3.1.3 Типы динамической памяти (FPM, EDO, BEDO,
SDRAM)
Временная диаграмма,
приведенная на рис.1, может
быть модифицирована для случая последовательного обращения к ячейкам,
принадлежащим к одной строке матрицы. В этом случае адрес строки
выставляется на шине только один раз и сигнал RAS#
удерживается на низком уровне на время всех последующих циклов
обращений, которые могут быть как циклами записи, так и чтения.
Такой режим обращения называется режимом быстрого страничного
обмена FPM (Fast Page Mode), иногда просто Page Mode, его временная диаграмма приведена на рис.5.
Понятие “страницам на самом деле относится к строке (row), а состояние с низким уровнем сигнала RAS#
называется “открытой страницей”. Преимущество данного режима заключается
в экономии времени за счет исключения фазы выдачи адреса строки
из циклов, следующих за первым, что позволяет повысить производительность
памяти. Для памяти с временем доступа 60
нс время цикла обмена внутри страницы может быть сокращено до
35 нс. Способность работать в режиме
FPM является “заслугой” не микросхем
или модулей памяти (в этом режиме способны работать и самые “древние”
микросхемы, и микросхемы EDO,
о которых речь пойдет ниже), а контроллера динамической памяти
(то есть чипсета). Однако по сложившейся терминологии обозначение
FPM относят к “стандартным” микросхемам и модулям динамической
памяти, которые не являются EDO, BEDO
или SDRAM. Иногда их все-таки
более точно называют стандартными (Std). Преимуществами FPM позволяет воспользоваться конвейерная адресация, применяемая
в процессорах, начиная с 80286.
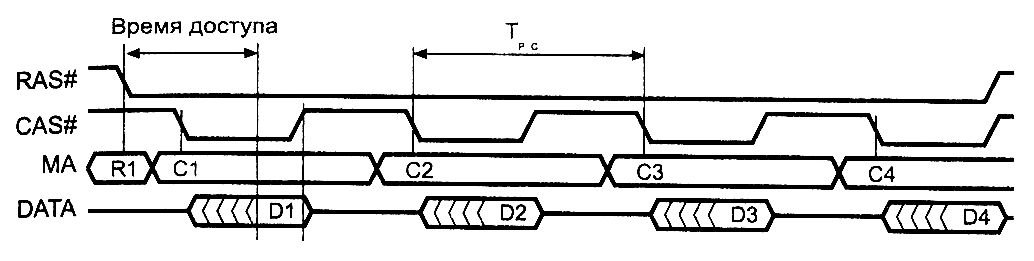
Рис.5. Страничный режим считывания стандартной DRAM
(FPM)
Обратим внимание
на то, что информация на выходе микросхем стандартной
DRAM появляется с некоторой задержкой относительно спада импульса
CAS# и держится только во время его низкого уровня. После подъема
CAS# выходной буфер микросхемы переводится в третье (высокоимпедансное)
состояние. Стандартная память со временем доступа 60-70
нс в режиме быстрого страничного обмена при частоте системной
шины 66 МГц может обеспечить
лучший пакетный цикл чтения 5-3-3-3.
Следующей модификацией памяти, направленной на повышение
производительности при том же быстродействии запоминающих элементов,
явилась память EDO (Extended или Enhanced Data Out) DRAM.
Эта память содержит регистр-защелку (data latch) выходных данных, что обеспечивает некоторую конвейеризацию
работы для повышения производительности при чтении. Регистр “прозрачен”
при низком уровне сигнала CAS#, а по его подъему фиксирует текущее значение выходных данных
до следующего его спада. Перевести выходные буферы в высокоимпедансное
состояние можно либо подъемом сигнала ОЕ# (Output Enable),
либо одновременным подъемом сигналов CAS# и RAS#, либо импульсом
WE#, который при высоком уровне
CAS# не вызывает записи (в
PC управление по входу ОЕ# практически
не используют).
Временная диаграмма
работы с EDO-памятью в режиме страничного обмена приведена на
рис.6, этот режим иногда называют
гиперстраничным режимом обмена НРМ (Hyper Page mode).
Его отличие от стандартного заключается подъеме
импульса CAS# до появления
действительных данных на выходе микросхемы. Считывание выходных
данных может производиться внешними схемами вплоть до спада следующего
импульса CAS#, что позволяет
экономить время за счет сокращения длительности импульса
CAS#. Время цикла внутри страницы
Для памяти со временем доступа 60
нс уменьшается с 35 нс (28,5 МГц) у стандартной
DRAM до 25 нс (40 МГц) у
EDO, повышая производительность в
страничном режиме на 40%. EDO-память со временем доступа
60-70 нс в режиме гиперстраничного
обмена при частоте системной шины 66
МГц может обеспечить лучший пакетный цикл чтения 5-2-2-2. Благодаря простоте данного усовершенствования при одном
и том же времени доступа запоминающих элементов цена EDO-памяти
почти не отличается от цены стандартной памяти. Однако ее применение
дает эффект, соизмеримый с эффектом от установка стандартного
асинхронного внешнего кэша. Более того, установка такого кэша
в систему с EDO-памятью практически не дает повышения производительности.
В результате распространилось мнение, что в EDO-памяти содержится
внутренний кэш, однако для простого регистра-защелки название
“кэш” звучит слишком торжественно.
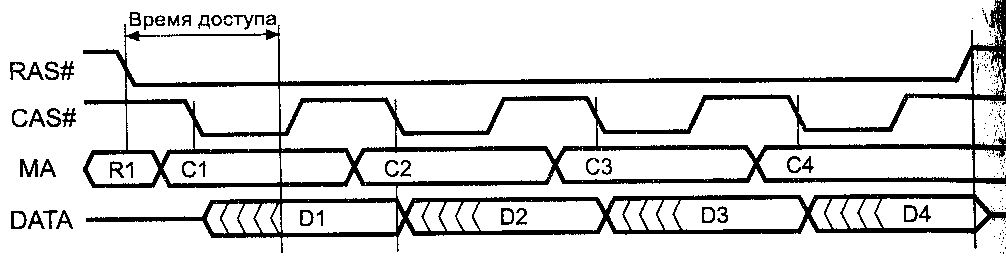
Рис.6. Страничный режим считывания
EDO DRAM (HPM)
Микросхемы
EDO DRAM применяются в современных
SIMM-72 и DIMM-модулях, эти
модули конструктивно и по назначению выводов совместимы со стандартными
(FPM). Все EDO-модули не имеют бит паритета (однобитные микросхемы
EDO не выпускаются). Контрольные
разряды 36-битных EDO-модулей могут использоваться только в ЕСС-памяти, в
которой доступ осуществляется всегда сразу ко всем байтам.
Установка EDO DRAM вместо стандартной в неприспособленные
для этого системы может вызвать конфликты выходных буферов устройств,
разделяющих с памятью общую шину данных. Скорее всего этот конфликт
возникнет с соседним банком памяти при использовании чередования
(Bank Interleaving). Для отключения
выходных буферов EDO-памяти внутри страничного цикла обычно используют
сигнал WE#, не вызывающий
записи во время неактивной фазы CAS# (рис.7,
кривая а). По окончании цикла буферы отключаются лишь по
снятию сигнала RAS# (рис.7, кривая б).
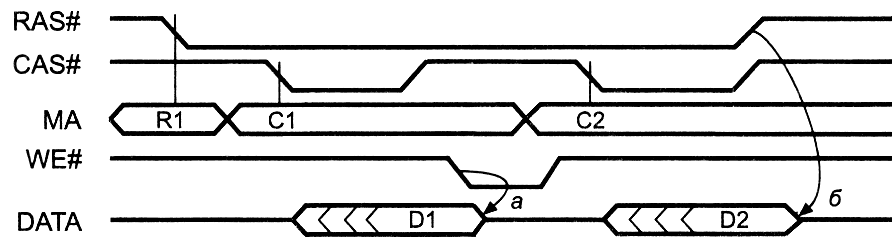
Рис.7. Управление
выходным буфером
EDO DRAM
Из принципиального
различия в работе выходных буферов следует, что в одном банке
не стоит смешивать модули EDO
и стандартные. EDO-модули поддерживаются не всеми чипсетами и
системными платами (в большей мере это относится к системным платам
для процессоров 486). Кроме
того, не все системные платы, поддерживающие EDO-память, используют
потенциальный выигрыш в производительности от ее “малой конвейеризации”
(это замечание больше относится к дешевым системным платам). Задержка
отключения выходных буферов затрудняет применение чередования
банков, из-за чего некоторые системные платы не поддерживают
Bank Interleaving для EDO-памяти.
Многие современные
чипсеты совместно с BIOS автоматически
определяют тип установленных модулей и даже допускают смесь
EDO и стандартных модулей в разных
банках. Для определения типа чипсет организует специальный цикл
обращения, в котором “прощупывает” все банки и заполняет таблицу,
после чего переводится в режим нормального обращения (с таким
специальным циклом возможна и обычная работа с памятью, но ее
производительность будет на удивление низкой). В нормальном режиме
обращения в зависимости от адреса, определяющего номер банка,
по значению соответствующего ему полю таблицы будет организован
требуемый цикл.
Микросхемы
EDO применяются как в основной памяти,
так и в видеопамяти современных графических адаптеров.
Результатом дальнейшего
развития конвейерной архитектуры модулей памяти явилась
BEDO (Burst EDO) DRAM. В микросхемах
данного типа кроме регистра-защелки выходных данных, стробируемого
теперь по фронту импульса CAS#, содержится еще и внутренний счетчик адреса колонок для
пакетного цикла. Это позволяет выставлять адрес колонки только
в начале пакетного цикла (рис.8),
а во 2-й, 3-й и 4-й передачах импульсы CAS# только запрашивают очередные данные. В результате удлинения
конвейера выходные данные как бы отстают на один такт CAS#,
зато следующие данные появляются без тактов ожидания процессора,
чем обеспечивается лучший цикл чтения 5-1-1-1 для BEDO-памяти со временем доступа 60
нс при частоте шины до 66 МГц. Задержка появления первых данных пакетного цикла
окупается повышенной частотой приема последующих. BEDO-память
применяется в модулях SIMM-72 и
DIMM, но поддерживается далеко не
всеми чипсетами.
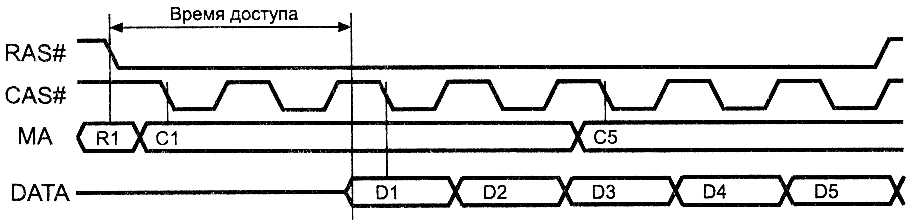
Рис.8.
Страничный режим считывания BEDO DRAM
Наиболее перспективна
SDRAM (Synchronous DRAM) — быстродействующая
синхронная динамическая память, работающая на частоте системной
шины без тактов ожидания внутри пакетного цикла, и обеспечивающая
цикл чтения 5-1-1-1
на частотах до 100 МГц. От
обычной (асинхронной) динамической памяти, у которой все внутренние
процессы инициируются только сигналами RAS#, CAS#
и WE#, память SDRAM
отличается использованием постоянно присутствующего сигнала тактовой
частоты системной шины. Это позволяет создавать внутри микросхемы
высокопроизводительный конвейер на основе ячеек динамической памяти
со вполне обычным временем доступа (50-70 нс). Синхронный интерфейс обеспечивает трехкратный выигрыш
в производительности по сравнению с традиционными микросхемами
DRAM, имеющими запоминающие ячейки
с тем же быстродействием. Микросхемы SDRAM
являются устройствами с программируемыми параметрами, со своим
набором команд и внутренней организацией чередования банков. Кроме
команд записи и чтения с программируемыми параметрами пакетного
цикла имеются команды автоматической регенерации и перевода в
режим хранения данных с пониженным энергопотреблением. Длина пакетного
цикла чтения и записи (burst length) может
программироваться (1, 2, 4, 8
или 256 элементов), цикл может
быть прерван специальной командой (без потери данных). Задержка
данных (количество тактов) относительно команды чтения
(read latency) программируется для
оптимального согласования быстродействия памяти с частотой системной
шины. Конвейерная адресация позволяет инициировать очередной цикл
обращения до завершения предыдущего. Автоматическая регенерация
(цикл CBR) выполняется по
командам “Auto Refresh” (REFR),
для сохранения информации требуется выполнение команд REFR с периодом 15,6 мкс
(стандартная регенерация, 4096 команд за 64 мс). Существуют
и модификации с пониженной частотой регенерации (extended
refresh). По команде “Self
Refresh” (SLFR) память переходит
в режим саморегенерации, для которой не требуется никаких внешних
обращений. В этом режиме операции чтения и записи запрещены. Возможен
также и перевод в режим хранения с пониженным потреблением, при
котором отключается питание внешних буферов. На рис.9 приведены временные диаграммы пакетных циклов записи и
чтения синхронной памяти. Все входные сигналы считаются действительными
во время положительного перепада тактового сигнала CLK.
Текущая команда определяется комбинацией сигналов на управляющих
входах RAS#, CAS#, WE#, All и AID при низком уровне
CS#. Набор команд включает следующие:
- MRS (Mode Register Set) — программирование
параметров.
- ACTV x (Bank activate/row-address entry) —
активация банка и ввод адреса строки, х ~ внутренний банк: Т
(Top) - “верхний”, В (Bottom)
- “нижний”.
- WRT x (Column-address entry/write operation) —
команда записи и ввод адреса столбца.
- READ x (Column-address entry/read operation) —
команда чтения и ввод адреса столбца.
- DEACx (Bank deactivate) — деактивация
банка, предзаряд (precharge) RAS.
- REFR (Auto-refresh), NOOP (No Operations), STOP
и DESL (Deselect) - вспомогательные
команды.
- SLFR (Self-refresh), PDE (Power-down entry), HOLD -
команды саморегенерации и энергосбережения, вводящиеся с помощью
сигнала СКЕ.
- MASK, ENBL — команды разрешения
операций с байтами для каждого такта пакетного цикла, вводимые
сигналами DQMx.
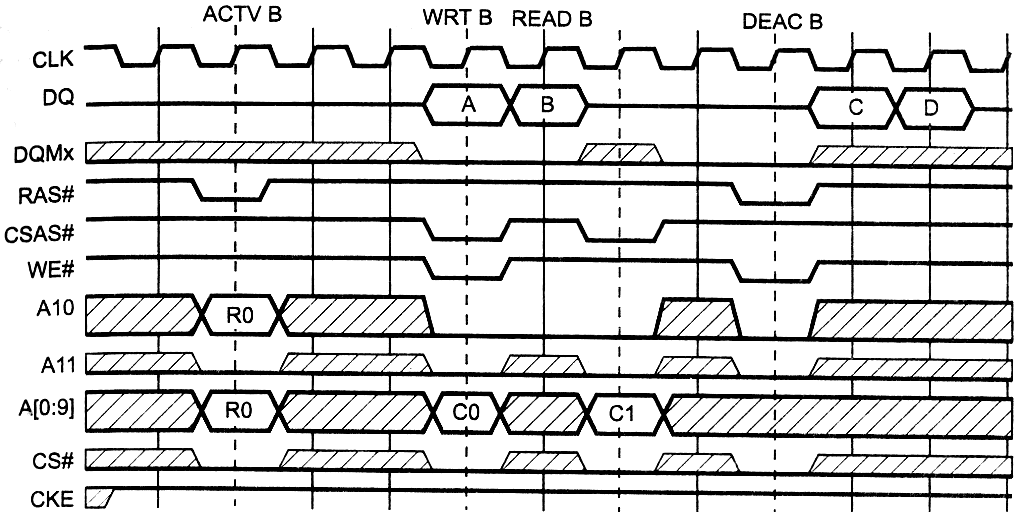
Рис.9. Временные диаграммы пакетных циклов SDRAM:
А и В
— данные для записи по адресу R0/С0 и
R0/C0+1; С и D —данные,
считанные по адресу R0/C1
и RO/C1+1
Обратим внимание, что внутренний счетчик адреса
работает по модулю, равному запрограммированной длине пакетного
цикла (например, при burst Length = 4 он не позволяет перейти
границу обычного четырехэлементного пакетного цикла). Кроме того,
порядок счета адресов внутри пакетного цикла соответствует специфическому
порядку (interleaved), принятому в процессорах i486 и старше.
Микросхемы синхронной памяти обычно имеют сигнал, выбирающий режим
счета: чередование (для процессоров Intel) или последовательный
счет (для Power PC).
По причине существенного
отличия интерфейса микросхемы SDRAM
не могут быть установлены в модули SIMM, они применяются в DIMM или устанавливаются прямо на системную (или графическую)
плату.
3.1.4. Сравнительная характеристика типов динамической
памяти
Основные характеристики описанных типов DRAM
приведены в табл.1. Обратим внимание на то, что спецификация (последний
элемент обозначения микросхем или модулей) для асинхронной памяти
указывает время доступа в единицах или десятках наносекунд, в
то время как для SDRAM она
указывает длительность цикла. Время доступа ТRAC
измеряется от начала операции чтения (спада RAS#) до появления достоверных данных на выходе. Длительность
цикла CAS определяет период поступления очередных данных на выходные
шины в середине пакетного цикла. Максимальная частота определяется
как частота системной шины, при которой число тактов на цикл не
превышает значений, провозглашенных оптимальными для данного типа
памяти. Поскольку она определяется не только собственно микросхемами
памяти, но и задержками окружающих ее элементов (коммутирующих
элементов чипсета, внешних буферов), длины проводников, емкостной
нагрузки на шины (зависящей и от количества посадочных мест и
установленных элементов памяти), в реальных системных платах возможны
и иные соотношения. Например, плата на чипсете 82430-ТХ позволяет
на частоте шины 66,6 МГц использовать EDO DRAM 60 нс циклом 5-2-2-2.
Таблица 1. Основные характеристики распространенных
типов DRAM
|
FPM
|
EDO
|
BEDO
|
SDRAM
|
|
Спецификация
|
-5, -6, -7
|
-5,-6. -7
|
-5,-6, -7
|
-10,-12,-15
|
|
Время доступа
(TRAC), нс
|
50, 60, 70
|
50, 60, 70
|
50, 60, 70
|
50, 60,70
|
|
Длительность
цикла CAS, нс
|
30,35,40
|
20,25,30
|
15, 16,6, 20
|
10, 12,15
|
|
Максимальная частота при пакетном цикле
чтения, МГц
|
66, 50, 40 5-3-3-3
|
66, 50, 40 5-2-2-2
|
66,60,50 5-1-1-1
|
100,80, 66 5-1-1-1
|
Время доступа и
длительность первого цикла чтения у всех четырех типов DRAM одинаковы, существенная разница наблюдается в последующих
трех циклах. Если чипсет способен генерировать обращения к памяти
в смежных циклах (back-to-back)
в режиме страничного обмена, то выигрыш в производительности будет
еще более значительным (вместо двух циклов 5-1-1-1
и 5-1-1-1 будет один 5-1-1-1-1-1-1-1}.
Динамической памяти с действительно произвольным доступом,
выполняемым с частотой 66
МГц, нет, для этого требуется память со временем доступа 15
нс, что пока недостижимо. В настоящее время наибольшее распространение
имеет память EDO, но при переходе на высокие частоты системной шины ожидается
вытеснение этой памяти микросхемами SDRAM.
Память BEDO является промежуточным
шагом, поскольку она эффективна только до частоты 66 МГц.
3.1.5. Маркировка микросхем динамической памяти
Современные микросхемы DRAM имеют емкость 1-256
Мбит, время доступа 45-250 нс и обычно организованы по 1, 4, 8,
9, 16, 18, 32 и 36 бит в корпусе с общими управляющими и адресными
сигналами. Микросхемы разрядностью 16/18 бит состоят из двух половин
по 8/9 бит, эти половины имеют раздельные сигналы CAS# или (и)
WE#, что обеспечивает возможность побайтного обращения. Микросхемы
32/36 бит делятся на четыре части. В зависимости от модификации
микросхемы выбор байт для записи может осуществляться либо двумя
(четырьмя) раздельными линиями CAS# при общей линии WE#, либо
раздельными линиями WE# при общей линии CAS#.
Существуют 4-битные
микросхемы с раздельными сигналами CAS# — QCAS (Quadro
CAS), предназначенные для хранения бит паритета сразу четырех
байт.
Маркировка микросхем несет информацию об изготовителе,
объеме и организации матрицы, типе памяти, быстродействии, напряжении
питания, дате изготовления и некоторую другую. Единой строгой
системы, применимой ко всем микросхемам, нет. В обозначении можно
выделить основную цифровую часть, которая для старых микросхем
(емкостью до 1 Мбит) имеет
примерно следующий вид:
4NC-T, где
4 — разрядность ячеек, бит, N-=1; С=64, 128, 256, ООО...
— количество ячеек (64:64К, 000:1М);
Т — время доступа в наносекундах или десятках наносе-кунд.
Первая цифра “4” обозначает класс памяти —
динамическая, но вместо нее могут встречаться и другие цифры и
комбинации (например, 5, 51). Примеры обозначений: 41256 — микросхема 256 Kxl, 44256 — микросхема 256 Кх4.
Для новых микросхем
разрядность обычно указывается последними тремя цифрами основной
части: 000, 100 — 1 бит;
400, 800 и 160 — 4, 8
и 16 бит соответственно. Ненулевое
значение последней цифры может задавать тип памяти (например,
EDO). Перед разрядностью указывается общий объем памяти в мегабитах.
Перед цифровой частью обычно стоит закодированное имя производителя:
HМ Hitachi
HY Hyundai
KM Samsung
М OKI
MCM Motorola
МТ Micron
ТММ Toshiba
TMS Texas Instruments
(n)PD NEC
После цифровой
части через дефис или букву, определяющую тип корпуса, указывается
спецификация быстродействия — время доступа в единицах или десятках наносекунд. Быстродействие
может указываться и отдельной надписью, например -6 и -60 означают время
доступа 60 нс. Примеры основной
части обозначения:
1000, 1100 – 1 M x 1 бит
4000, 4100 – 4 M x 1 бит;
4400 – 1 M x 4 бит
16400, 17400 – 4 M x 4 бит; 16100 – 16 M x 1 бит; 16160 – 1 M x 16 бит;
64400 – 16 M x 4 бит;
64800 – 8 M x 8 бит;
64160 – 4 M x 16 бит.
3.1.6.
Виды модулей памяти
Современные модули
памяти имеют шину данных разрядностью 1, 4
или 8 байт. Кроме основных
информационных бит, модули могут иметь дополнительные контрольные
биты с различной организацией:
- Модули без контрольных бит (поп
Parity) имеют разрядность 8, 32 или 64 бита и
допускают независимое побайтное обращение с помощью отдельных
для каждого байта линий CAS#.
- Модули с контролем паритета
(Parity) имеют разрядность 9, 36 или 72 бита и
также допускают независимое побайтное обращение, контрольные
биты по обращению приписаны к соответствующим байтам.
- Модули с генератором паритета
(Fake Parity, Parity Generator, Logical Parity) также
допускают независимое побайтное обращение, логические генераторы
паритета по чтению приписаны к соответствующим байтам. Действительного
контроля памяти они не обеспечивают.
- Модули с контролем по схеме
ЕСС имеют разрядность 36, 40, 72
или 80 бит. Обычно они допускают побайтное обращение к информационным
битам, но контрольные биты у них привязаны к одному или нескольким
сигналам CAS#, поскольку
ЕСС подразумевает обращение сразу к целому слову.
- ECC-Optimized — модули,
оптимизированные под режим ЕСС. От обычных ЕСС модулей они отличаются
тем, что могут не обеспечивать побайтное обращение и к информационным
битам.
- ECC-on-Simm (EOS) — модули
со встроенной схемой исправления ошибок. Каждый байт модуля
имеет встроенные средства контроля и исправления ошибок, работающие
прозрачно. Для системы модули функционируют как обычные паритетные
— в случае обнаружения неисправимой
ошибки они генерируют ошибочный бит паритета. Эти модули обеспечивают
отказоустойчивость по памяти (Kill Protected Memory) для системных плат, поддерживающих только контроль
паритета. По благородству поведения (делают больше, чем “говорят”)
они являются прямой противоположностью модулям с генератором
паритета.
3.1.7. Способы
крепления модулей памяти на плате:
- Пайка – первые
микросхемы памяти припаивались к плате, следовательно, их практически
было невозможно поменять
- Установка в "кроватку"
(модули DIP) – такие микросхемы устанавливались в специальный паз
на системной плате ("кроватку") и их относительно
легко было заменить, но с увеличением объема памяти ее микросхемы
стали занимали много места на плате.
Рис.10. Модуль DIP
- Модули SIMM
– были созданы для экономии места на системной плате следующим
образом: на специальную печатную плату с двух сторон припаиваются
микросхемы памяти, образуя модуль памяти. Каждый модуль
устанавливается контактами (выводами) в специальный разъем
(слот) на системной плате. Таких разъемой может быть несколько.
Они объединяются в группы, называемые банками памяти.
Первые модули SIMM были
30-контактные 8-разрядные емкостью 256 Кб, 512 Кб, 1 Мб, позже
появились 72-контактные 32-разрядные модули емкостью 4, 8, 16,
32, 64, 128 и даже выше. Первые 30-контактные модули SIMM появились
в последних моделях компьютеров 80286 и просущетсвовали до первых
моделей 80486. В более поздних моделях компьютеров 80486 использовались
уже 72-контактные модули SIMM. На модулях SIMM устанавливались
микросхемы FPM или EDO.
Рис.11. Модуль
SIMM
- Модули DIMM
– появились в 1997 году. Контакты таких модулей с двух сторон
электрически независимы, в отличие от модулей SIMM. Наиболее
распростанены 168-контактные 64-разрядные модули DIMM, имеющие
по 84 контакта с каждой стороны (рис.3). На модули DIMM устанавливаются
микросхемы SDRAM (реже EDO). В конструкции таких модулей предусмотрено
два ключа: первый служит для определения типа памяти (SDRAM
или EDO), второй – для определения напряжения питания (5 В
или 3,3 В). В настоящее время большинство системных плат
оборудовано слотами для установки DIMM-модулей.

Рис.12. Модуль DIMM
3.1.8. Организация
и заполнение банков памяти
Слоты для устновки модулей памяти объединяются
в банки. Количество модулей объединяемых в банк определяется соотношением
разрядности системной шины к разрядности модуля памяти. Следовательно,
каждый банк необходимо заполнить полность.
3.1.9. Модули внешней кэш-памяти
На современных материнских платах устанавливаются
модули внешней кэш-памяти. Необходимость этого вызвана тем, что
время доступа к ячейке оперативной памяти (60-100 нс) в 2-3 раза
ниже скорости работы процессора, поэтому процессор вынужден простаивать
2-3 цикла в ожидании, что ведет к снижению быстродействия компьютера
в целом. Поэтому для согласования работы сравнительно медленных
устройств, например, оперативной памяти, и снижения времени простоя
процессора, устанавливается сверхоперативная или кэш-память со
временем доступа 15-20 нс. Обмен данными между процессором и памятью
(как оперативной, так и внешней) осуществляется через кэш-память,
то есть данные из оперативнойй памяти сначала пересылаются в кэш-память
и только из нее считываются процессором. Претмущество такого способа
в том, что при повторном обращении к памяти данные уже находятся
в кэш-памяти и нет необходимости снова их считывать из медленнойй
оперативной памяти. Координацию работы кэш-памяти осуществляет
контроллер, который сообщает процессору, имеются ли в кэш-памяти
необходимые данные.
Кэш-память состоит из трех основных элементов (рис.13):
- Контроллера кэш-памяти
- Кэш-памяти данных (DataRAM)
- Кэш-памяти адресов (TagRAM)
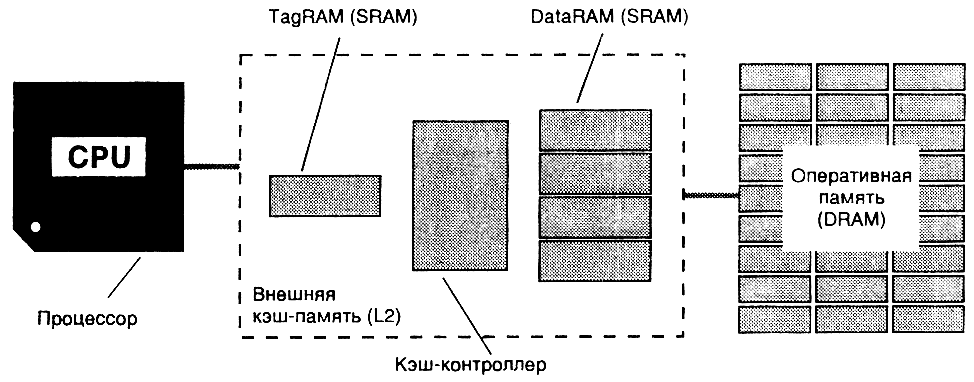
Рис.13. Элементы внешней кэш-пямяти
DataRAM представляет
собой кэш-память, в которой находятся данные. TagRAM содержит
информацию о адресах этих данных в кэш-памяти. В случае необходимости
процессор сначала обращается не к оперативной памяти, а к TagRAM.
Если при проверке адресов данных процессор обнаружит, что требуемых
данных в DataRAM нет, он обращается к более медленной оперативной
памяти.
3.1.10. Иерархия оперативной
памяти
Организация оперативной памяти в компьютере имеет
многоуровневую структуру. Виды памяти более высокого уровня имеют
меньший объем, но большую скорость доступа.
1 уровень: Внутренняя кэш-память (кэш-память
процессора, кэш-память первого уровня L1)
Для повышения производительсти
компьютера на базе процессоров 80486 и Pentium в состав процессоров включили еще внутренную кэш-память
емкостью 8 или 16 Мб. Ее назначение – согласование скорости работы
процессора и внешней кэш-памяти (кэш-памяти второго уровня L2).
Самая быстрая память.
2 Уровень:
Внешняя кэш-память (кэш-память второго уровня L2)
Впервые внешняя
кэш-память появилась на системных платах с процессором 80386,
имела емкость 128 Кб и использовалась для согласования частоты
работы процессора и оперативной памяти (RAM). Процессоры взаимодействовали с внешней кэш-памятью через
системную шину. Однако, с увеличением тактовой частоты работы
процессора скорость обмена данными между процессором и внешней
кэш-памятью стала “тормозить” производительность компьютера. Была
разработана отдельная шина для внешней кэш-памяти, названная двойная
независимая шина (Dual Independent Bus, DIP),
которая работает с большей тактовой частотой, чем системная шина.
В компьютерах с процессором Pentium Pro внешняя
кэш-память помещена не на системной плате, а непосредственно в
ядро процессора, и обмен данными между процессором и внешней кэш
памятью стал осуществляятся на частоте процессора. Понятие “внешняя
кэш-память” утратило смысл и появился термин – кэш-память второго
уровня. В совремнных компьютерах ее объем достигает 2 Мб.
содержание
|
